
Creating a Hindi ASR
This project was completed as part of Google Summer of Code 2019 under the mentorship of RedHen Lab. I’d like to thank Prof Dr TM
Thasleema, Central University Kerala and Karan Singla, PhD graduate student at USC Viterbi school of Engineering mentors of this project for their extended and comprehensive support without which this project wouldn’t have been completed. Also absolutely indebted to Prof Mark Turner, Case Western Reserve University, and Prof Francis Steen UCLA, for exceptional and quick support from the community side.
The scope of this project is to build a Hindi Speech Recognition Engine to transcribe news. However the lack of adequate datasets made this a really challenging task to complete. Hence this project is completed with a pre-recorded 150 sentences in Hindi spoken by 6 speakers.
Languages & Frameworks
This project was completely developed in the Kaldi Toolkit, and was run, tested and deployed in a Linux Ubuntu variant OS. The languages used include :
-
Shell
-
C
-
Perl
-
Python
-
Cpp
Timeline
-
Week 1 : The first week was spent on setting up the workspace in Red Hen Gallina space. This was done in accordance with the Red Hen guidelines (here)[http://www.redhenlab.org/home/tutorials-and-educational-resources/using-singularity-to-create-portable-applications]. The Singularity image was setup, followed by installation of Kaldi then the datasets were downloaded and formatted according to its structure.
-
Week 2 - 3 : Spent on pre-processing the English Datasets. Around approx 3000 hours of data was pre-processed and cleaned and made into a unified structure. Followed by feature extraction, initial HMM - GMM training.
-
Week 4 - 5 : DNN training was completed in this stage. This was trained on a Google Cloud machine with 8 GPUs and has to re-iterate various stages for correction and accuracy improvements.
-
Week 6 : Focused mainly on obtaining datasets for Hindi from LDC-IL at CIIL.
-
Week 7 : Focused mainly on building the Hindi ASR project with pre recorded 200 utterances spoken by 6 different speakers.
-
Week 8 : Completed the documentation and deployment of the project. Source code is available in Github . And the entire files has been uploaded to the the Red Hen Gallina Server. Available at :
/mnt/rds/redhen/gallina/home/sxk1497/gsoc2019
Development
The initial task is to properly curate the data. The initial raw text is in devanagari script, which is then converted to ILSL12 convention (which is used by Indian speech R&D community). This was done by first converting Indian-language text from UTF-8 Unicode Devanagari to ISCII format and then from ISCII to ILSL12 convention. Followed by which the data is prepared as per the Kaldi format, which includes the general files wav.scp, utt2spk, spk2utt, text etc .

Wav.scp file
![]()
ILSL12 converted transcript file
utt2spk file
. The next task is to create a Language Model from the lexicon files available. A bi-gram LM is trained for this purpose. In order to create:
./Create_ngram_LM.sh
The next step is to do the feature extraction (MFCC) over the Speech data before proceeding to the monophone training. In order to do monophone training :
for x in train test; do
utils/fix_data_dir.sh data/$x;
steps/make_mfcc.sh --cmd "$train_cmd" --nj "$feat_nj" data/$x $exp/make_mfcc/$x $mfccdir || exit 1;
steps/compute_cmvn_stats.sh data/$x $exp/make_mfcc/$x $mfccdir || exit 1;
utils/validate_data_dir.sh data/$x;
done
fi
Once the features are extracted in ark files, then the next step isto perform monophone training. A monophone model is an acoustic model that does not include any contextual information about the preceding or following phone. It is used as a building block for the triphone models, which do make use of contextual information. Once the monophone training is completed we also perform decoding with the same.
steps/train_mono.sh --nj "$train_nj" --cmd "$train_cmd" $train_dir $lang_dir $exp/mono || exit 1;
utils/mkgraph.sh --mono $lang_dir $exp/mono $exp/mono/$graph_dir || exit 1;
steps/decode.sh --nj "$decode_nj" --cmd "$decode_cmd" $exp/mono/$graph_dir $test_dir $exp/mono/$decode_dir || exit 1;
Once we do that we obtain the result as :
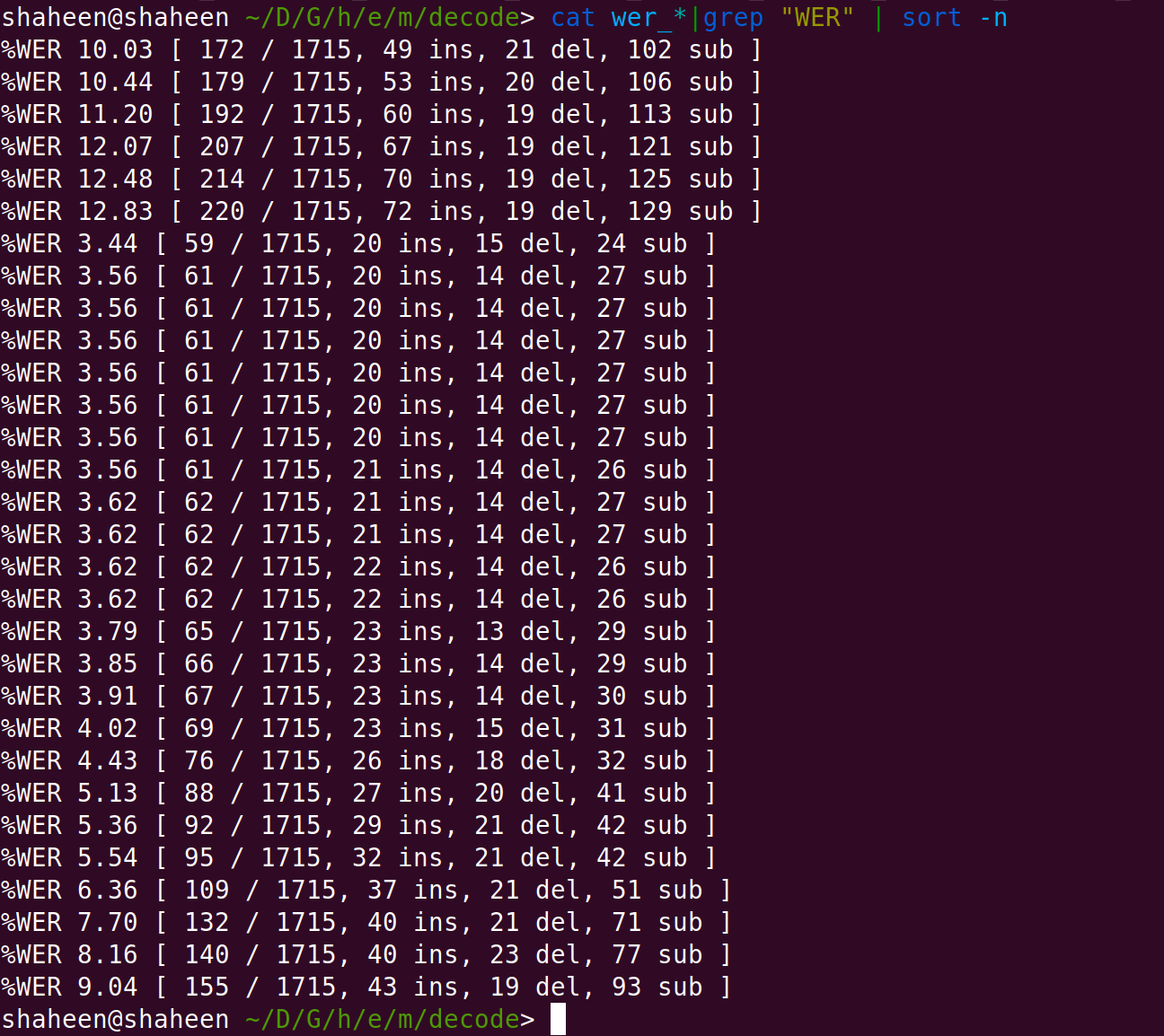
The next step is to construct a triphone model, which usese three phones. While monophone models simply represent the acoustic parameters of a single phoneme, we know that phonemes will vary considerably depending on their particular context. The triphone models represent a phoneme variant in the context of two other (left and right) phonemes.
steps/train_deltas.sh --cmd "$train_cmd" $sen $gauss $train_dir $lang_dir $exp/mono_ali $exp/tri_8_$sen || exit 1;
utils/mkgraph.sh $lang_dir $exp/tri_8_$sen $exp/tri_8_$sen/$graph_dir || exit 1;
steps/decode.sh --nj "$decode_nj" --cmd "$decode_cmd" $exp/tri_8_$sen/$graph_dir $test_dir $exp/tri_8_$sen/$decode_dir
Once the tri-phone model is trained, we also decode with the same model for weight optimization of the LM ,and it gives the output :
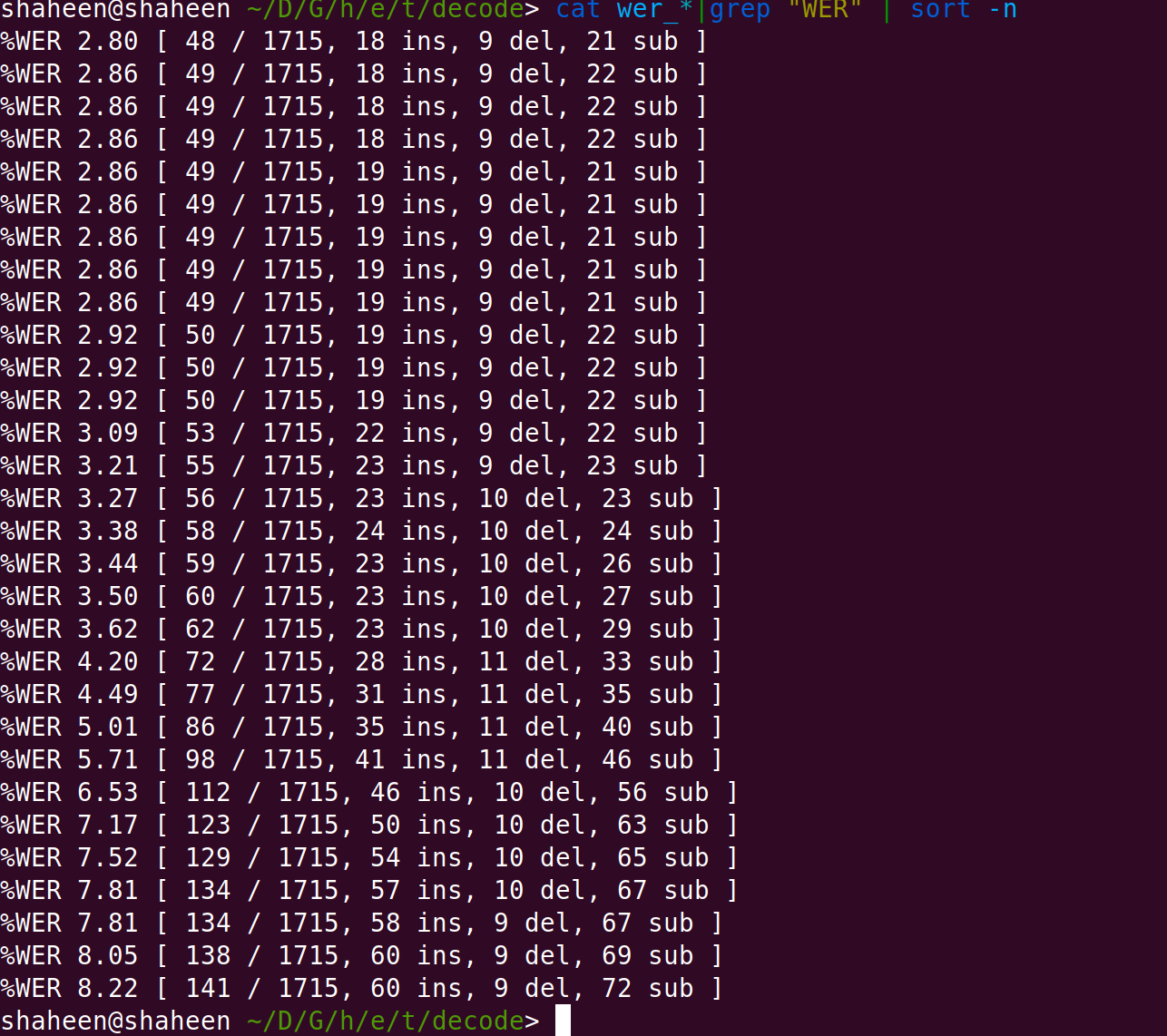
The next step is to perform the DNN training in Kaldi. Which is done using nnet2 here. This is again a variation of DNN-HMM training . Now the state observing/emission probability will be modelled by a Deep Neural Network.
In order to do so :
steps/nnet2/train_tanh.sh --mix-up 5000 --initial-learning-rate 0.015 \
--final-learning-rate 0.002 --num-hidden-layers 3 --minibatch-size 128 --hidden-layer-dim 256 \
--num-jobs-nnet "$train_nj" --cmd "$train_cmd" --num-epochs 15 \
$train_dir $lang_dir $exp/tri_8_2000_ali $exp/DNN_tri_8_2000_aligned_layer3_nodes256
Then we decode the trained model with the test set :
steps/nnet2/decode.sh --cmd "$decode_cmd" --nj "$decode_nj" \
$exp/tri_8_2000/$graph_dir $test_dir \
$exp/DNN_tri_8_2000_aligned_layer3_nodes256/$decode_dir | tee $exp/DNN_tri_8_2000_aligned_layer3_nodes256/\
$decode_dir/decode.log
which generates the final WER output of the training as :
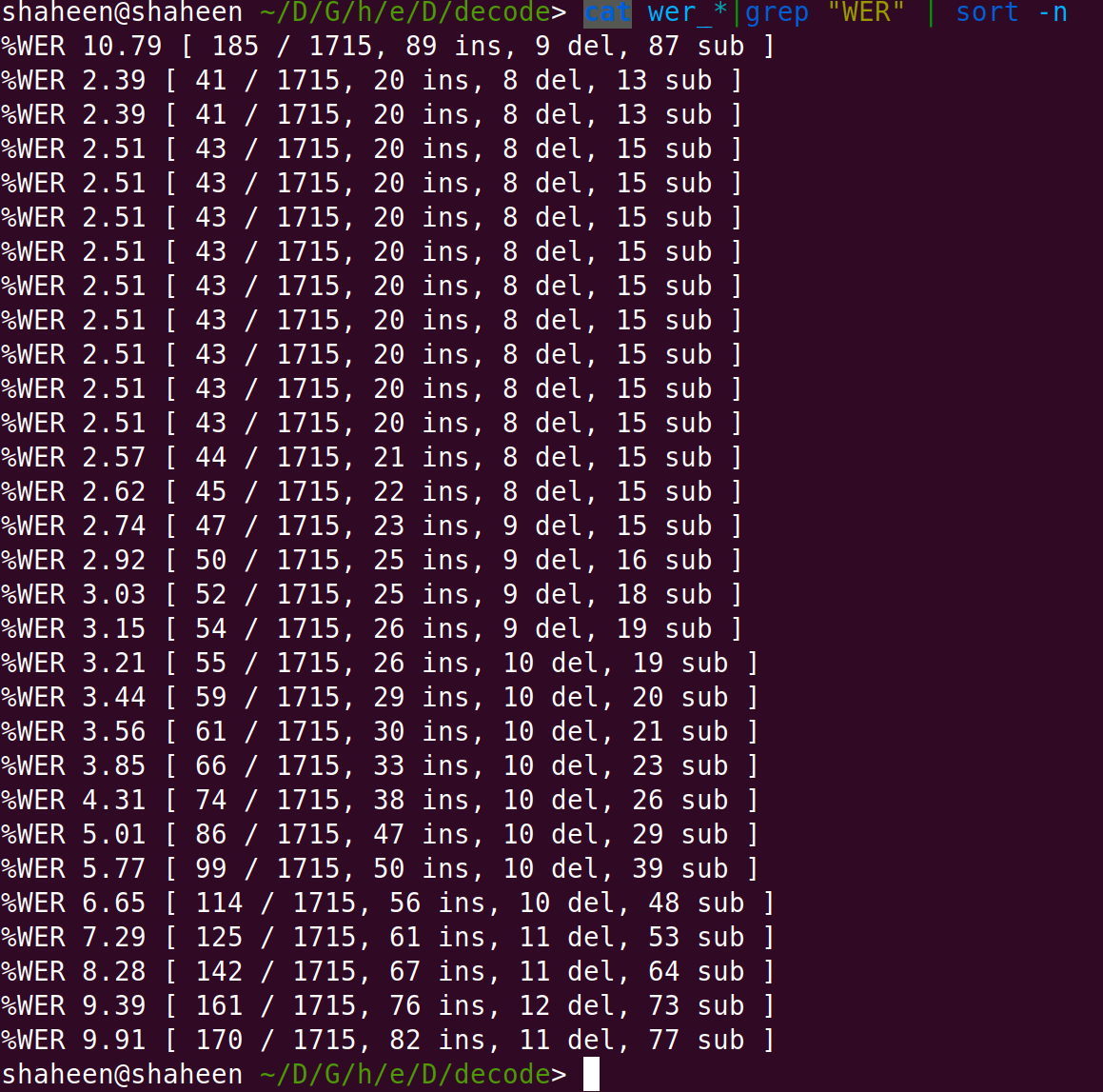
Future Work
The present model is trained with 200 utterances. However, by December, the LDC-IL is supposed to release another 120 annotated hours of dataset in Hindi. To improve the accuracy, the engine can be re-trained on that data to adapt to more test scenarios.
References
-
“Speech Recognition For Hindi Language”, Anushree Srivastava, Nivedita Singh, Shivangi Vaish. International Journal of Engineering Research & Technology (IJERT) , 2013
-
”The Kaldi SpeechRecognition Toolkit”D. Povey, A. Ghoshal, G. Boulianne, L. Burget, O. Glembek, N. Goel, M. Hannemann, P.Motlicek, Y. Qian, P. Schwarz, J. Silovsky, G. Stemmer, and K. Vesely. In IEEE 2011 Workshop on Automatic Speech Recognition and Understanding. IEEE Signal Processing Society, 2011.
-
“An Overview Of Hindi Speech Recognition” , Neema Mishra, Urmila Shrawankar, Dr. V. M Thakare. International Conference on Computational Systems and Communication Technology May 2010.
-
“Hindi Speech Recognition System Using HTK”. Kumar K, Aggarwal RK. International Journal of Computing and Business Research. 2011
I offer free AI consultations to help you explore how AI and Machine learning can be used to solve your business challenges.
I am available at : shaheenkdr [@] gmail [dot] com